模型
Google Magenta RealTime 2:实时音乐模型从“生成器”走向“可演奏乐器”
更新后的第三方研究简报引入 Google 官方图表,梳理 MRT2 的低延迟控制、MIDI/文本/音频输入、2.4B/230M 双模型结构、SpectroStream/MusicCoCa 链路,以及它和一键生成整首歌工作流的差异。
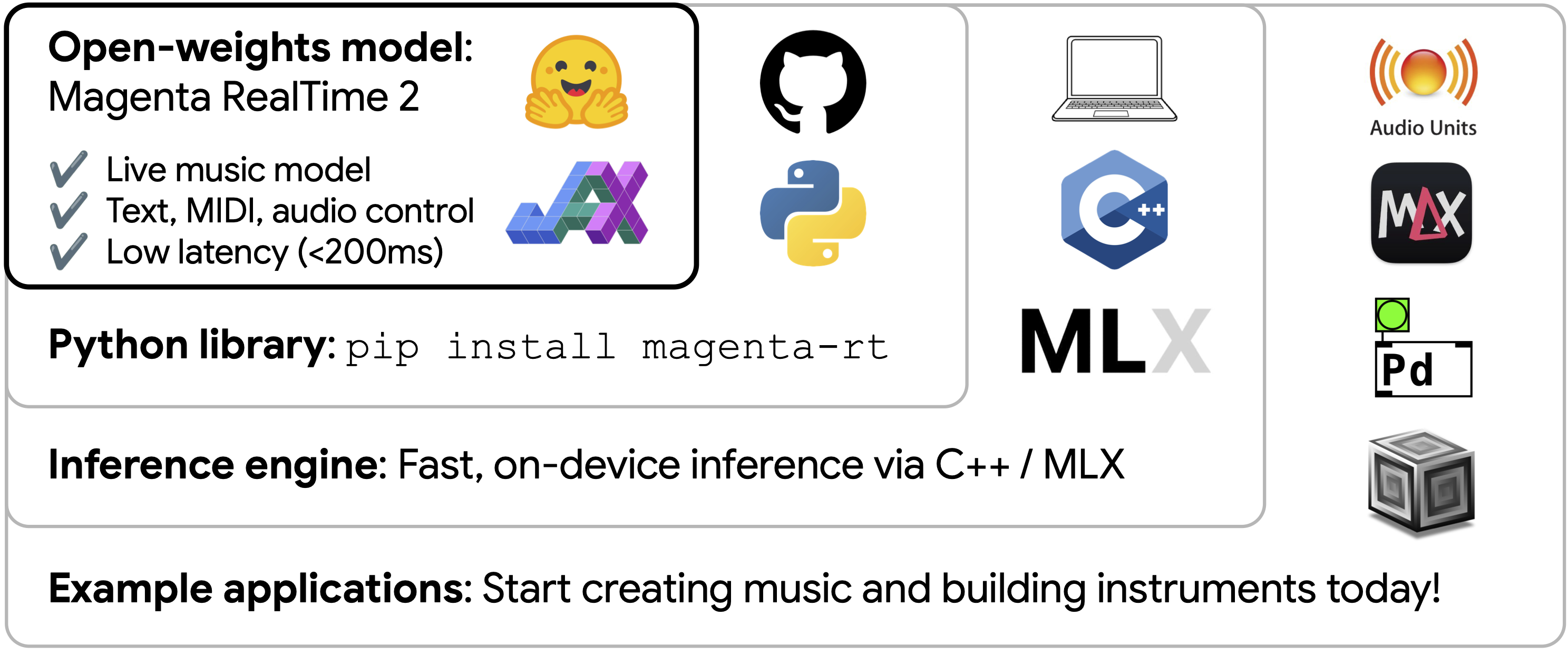
更新后的第三方研究简报引入 Google 官方图表,梳理 MRT2 的低延迟控制、MIDI/文本/音频输入、2.4B/230M 双模型结构、SpectroStream/MusicCoCa 链路,以及它和一键生成整首歌工作流的差异。
模型新闻 / Google Magenta
Google Magenta RealTime 2(MRT2)不是传统意义上“输入提示词、等待完整曲目”的音乐生成器。官方发布页把它定义为 open model、实时推理引擎和示例应用的组合:2.4B 参数 base 模型、230M 参数 small 模型、SpectroStream 音频 codec、MusicCoCa 风格表征、MIDI/文本/音频控制,以及可在本地设备上运行的实时音乐生成体验。
这篇更新版文章加入 Google 官方图表和模型卡证据,重点解释 MRT2 的独特位置:它不是要直接替代编曲、混音或完整歌曲制作,而是把 AI 音乐模型向“可演奏、可控制、可嵌入 DAW 和现场互动”的方向推进。换句话说,它更像一个实时合奏对象,而不是一台离线出歌机器。
过去两年,AI 音乐最容易被理解成“把一句话变成一首歌”。Suno、Udio 这类 prompt-to-track 工作流把创作门槛降得很低,但交互节奏仍接近离线渲染:写提示词、等待结果、挑版本、再改提示词。MRT2 的路线不同,它把音乐模型放回时间轴里,让用户在听到输出的同时继续用 MIDI、文本和音频改变它。
这就是“从生成器到乐器”的关键:乐器不是一次性吐出成品,而是持续响应演奏者。MRT2 的价值也不应该只问“它能不能写完整歌曲”,而应该问“它能不能被表演、能不能被控制、能不能进入音乐人的实时工作流”。从这个角度看,MIDI 输入比参数规模更重要,因为 MIDI 把模型输出和演奏动作绑定到同一个时间维度里。
Google 官方发布页也延续了 Magenta 长期的立场:AI 是音乐人的工具,而不是替代者。MRT2 的设计选择很符合这条路线。它强调实时控制、DAW 插件、示例应用和本地推理,而不是把模型包装成自动作曲家。

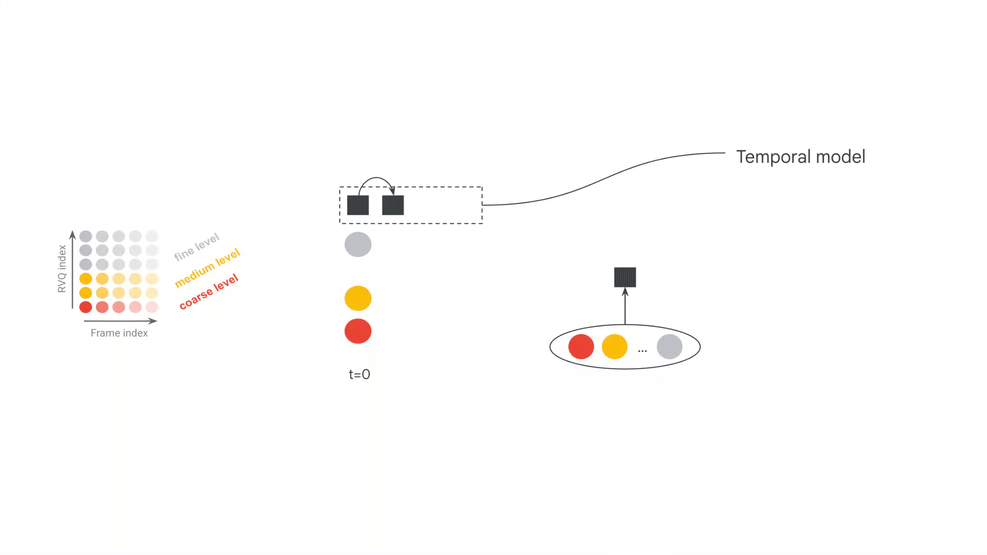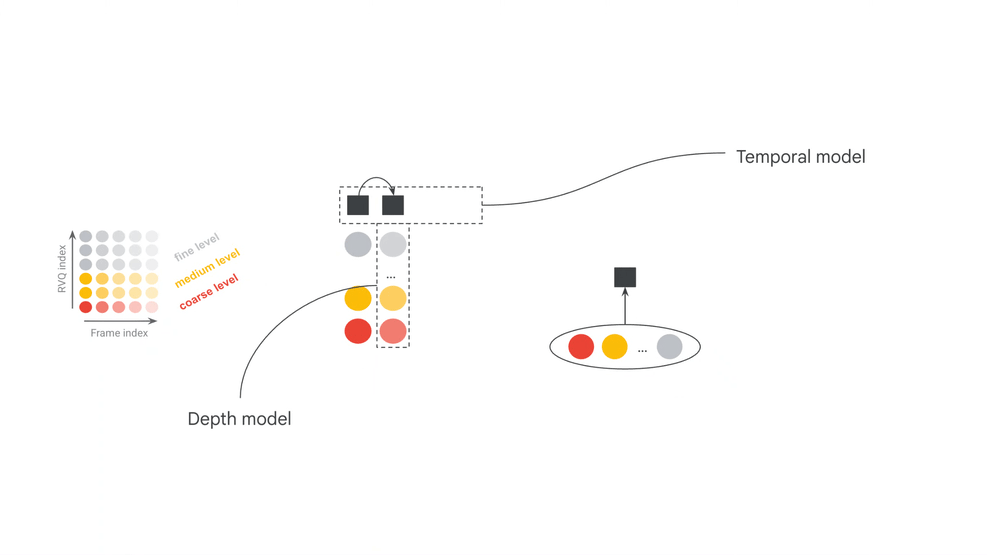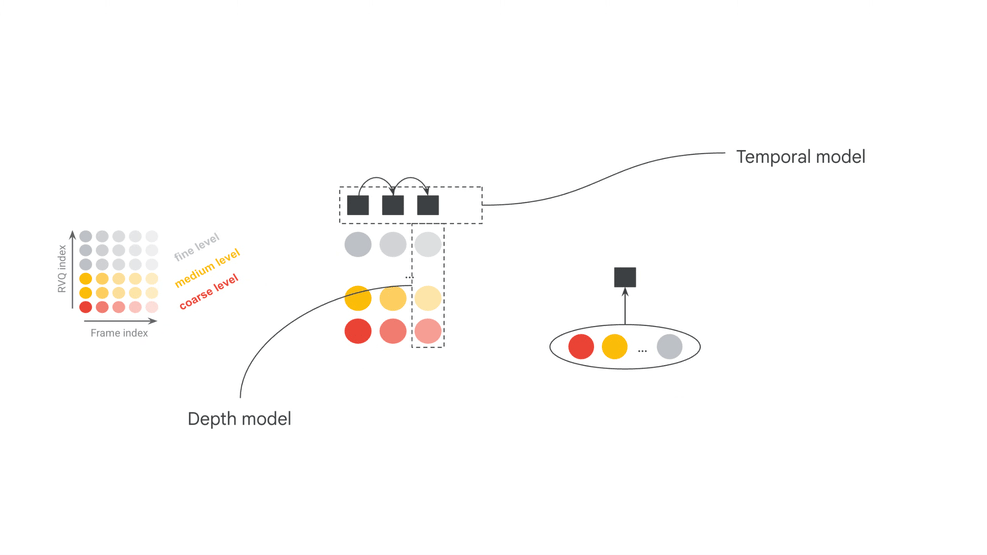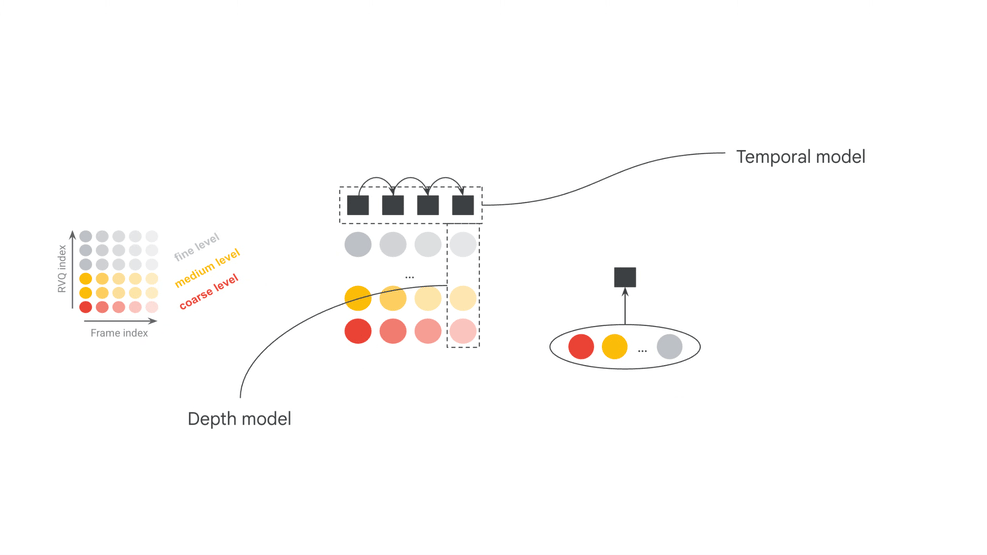
官方模型卡把 MRT2 拆成三个核心部件:SpectroStream、MusicCoCa 和 decoder-only Transformer LLM。SpectroStream 是离散音频 codec,用于把 48kHz stereo 音乐音频转换为 tokens;MusicCoCa 把文本和音乐音频映射到共同 embedding 空间;LLM 则在上下文音频 tokens、MusicCoCa 风格 tokens 和 MIDI tokens 条件下生成下一帧音频 tokens。
这套结构解释了为什么 MRT2 能同时接受文本、音频和 MIDI。文本适合描述风格,音频适合提供声音/音乐参考,MIDI 则提供演奏层面的实时控制。它不是把三种输入简单拼接,而是把它们分别放到“风格、上下文、时间动作”三个位置。
官方资料给出的两个模型配置也很有信息量:base 为 2.4B 参数,small 为 230M 参数。base 更偏质量,small 更偏本地运行门槛;模型卡中还列出 base 25 frame(1s)windowed attention、small 41 frame(约 1.6s)windowed attention,并说明两者有效接收域都是 20s。这个设计说明 MRT2 不是离线理解整首歌,而是在有限上下文窗口里做持续生成。
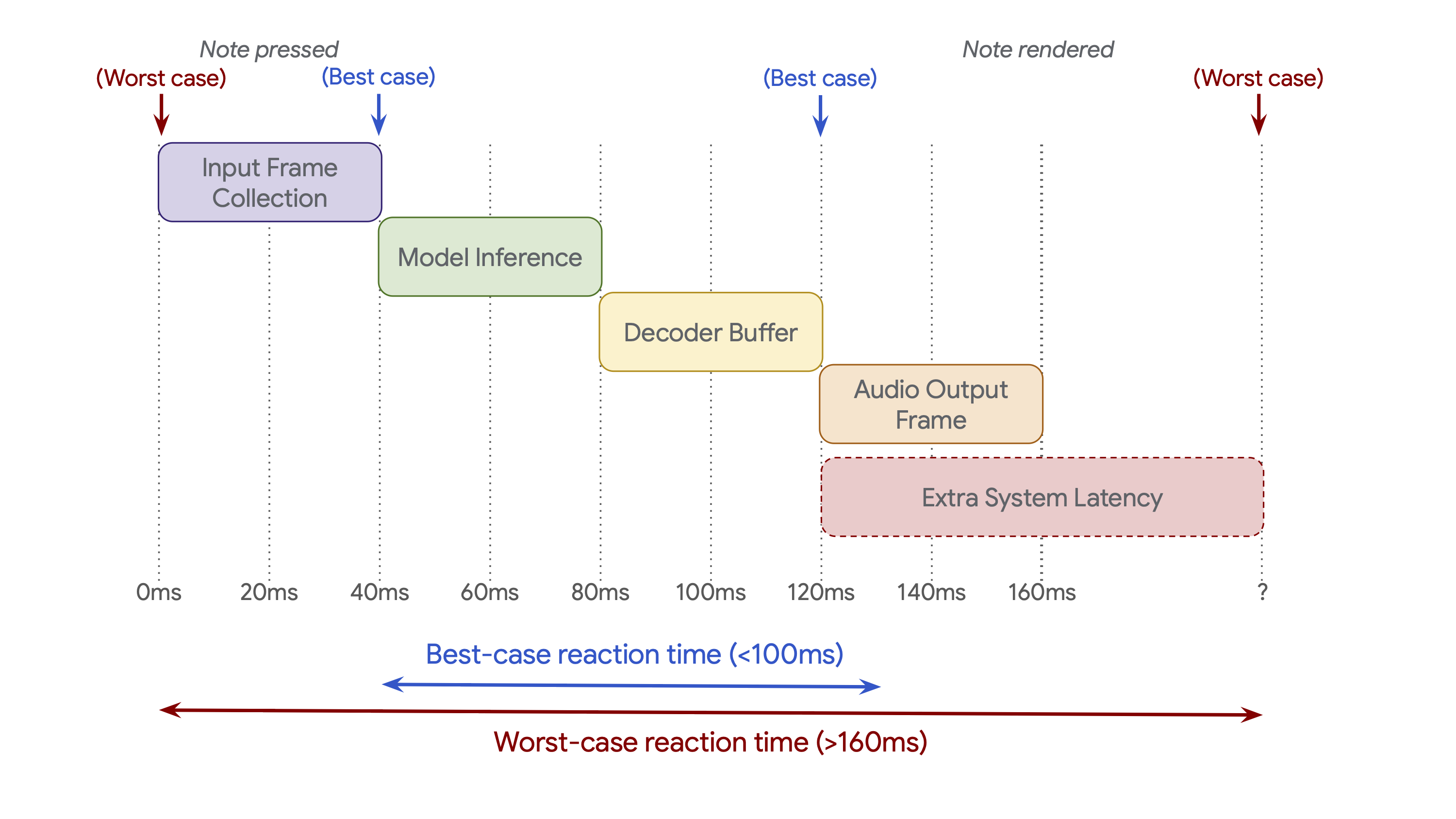
Google 官方页给出的关键变化之一,是相对前代把模型帧长从 2s 降到 40ms,并把控制延迟从约 3s 降到约 200ms。这个数字很有吸引力,但必须准确理解:官方也指出,端到端反应时间不只由模型推理决定,还包括输入缓冲、输出缓冲、音频接口、宿主软件和外部组件带来的额外延迟。
对音乐人来说,200ms 左右并不等于传统硬件乐器那种几乎即时的触键响应,但它足以把模型从“离线生成器”推向“可互动系统”。它更适合风格变形、伴奏延展、音色/纹理响应、live coding、装置艺术和游戏音乐,而不是替代一个需要毫秒级精准触发的鼓机或钢琴音源。
| 维度 | Magenta RealTime 2 | 常见 prompt-to-track 生成器 | 对用户的实际影响 |
|---|---|---|---|
| 交互节奏 | 听、演奏、调整、继续生成。 | 输入提示词后等待完整结果。 | MRT2 更适合实时实验和演出,后者更适合快速拿到成品草稿。 |
| 控制输入 | MIDI、文本、音频共同控制。 | 通常以文本提示词和少量结构参数为主。 | MIDI 让模型能跟演奏动作发生关系。 |
| 运行位置 | 官方强调本地、open weights、Apple Silicon 示例应用和 DAW 插件。 | 多为云端服务。 | MRT2 更便于研究、插件和本地创作软件集成,但也要求本地硬件。 |
| 输出目标 | 连续、可被引导的音乐音频流。 | 完整歌曲或完整片段。 | MRT2 更像实时乐器/伴奏者,不是成品歌曲工厂。 |
| 创作边界 | 模型卡强调主要支持 instrumental music,并提到非词汇化 vocal sounds 的限制。 | 常以人声歌曲生成作为主要卖点。 | MRT2 更适合器乐、纹理、伴奏和互动音乐场景。 |
| 维度 | 官方资料 | 准确解读 |
|---|---|---|
| 许可 | 代码 Apache-2.0,模型权重 CC-BY 4.0。 | 不是单一许可;集成时要同时看代码、权重和使用条款。 |
| 模型规模 | 2.4B base / 230M small。 | base 与 small 对应质量和本地运行门槛的不同取舍。 |
| 音频 codec | SpectroStream 将 48kHz stereo 音频转换为 tokens,25Hz frame rate、64 RVQ depth、10 bit codes、16kbps。 | 实时性来自模型和 codec/流式表示的共同设计,而不只是采样率。 |
| 输入控制 | 文本、音频示例、MIDI。 | 三种输入分别承担风格、上下文和演奏状态控制。 |
| 训练数据 | 约 7.1 万小时 stock music,主要是器乐。 | 应谨慎期待人声歌词生成;模型卡也提示 vocal sounds 多为非词汇化。 |
| 评测 | 模型卡称 MRT2 技术报告和评测结果将后续发布。 | 当前不应编造排行榜或未公开分数;只能引用官方已给出的结构和限制。 |
MRT2 的关键词是 continuous generation 和 low-latency control。它适合被演奏和引导,而不是只被提示词命令。
官方模型卡把用途集中在 interactive music creation,并明确训练数据主要是 instrumental stock music。完整歌曲、人声歌词和商业发行仍需要人工制作流程。
开放权重和本地推理让研究、插件和 DAW 集成更现实,但硬件、缓冲、宿主软件和音频接口都会影响体验。
本文图片/GIF 均来自 Google Magenta 官方发布页,没有使用替代示意图或自制伪图表。